Paper to review: ImageNet Classification with Deep Convolutional Neural Networks
Main contributions:
- Improve the architecture of CNN
- Realize GPU implementation of CNN
- The first CNN reaches best performance in ImageNet Large-Scale Visual Recognition Challenge (ILSVRC)
In the post of review of LeNet-5, Yann LuCun succeeded to implement a CNN to recognize handwritten digits. He also explained to us how to design a CNN. However, the images to process in LeNet-5 is in the resolution of 32*32*1. In order to process high resolution images, we need to train CNN much faster. AlexNet is the first CNN, which could deal with high resolution images. The authors succeeded to train AlexNet by improving the architecture of CNN and implementing GPU code for CNN.
1. New architecture of CNN
1-1. ReLU Nonlinearity
ReLU stands for Rectified Linear Units. It’s firstly proposed in paper[2]. But it’s firstly integrate into CNN in this paper.
The traditional activation functions are saturating, such as sigmoid, $f(x) = (1 + e^{-x})^{-1}$, and $f(x) = tanh(x)$. While ReLU, $f(x) = max(0, x)$, is a non-saturating function, which significantly speed up the training of CNN. Image 1[1] shows the number of iterations required to reach 25% training error on the CIFAR-10 dataset for a particular four-layer convolutional network.
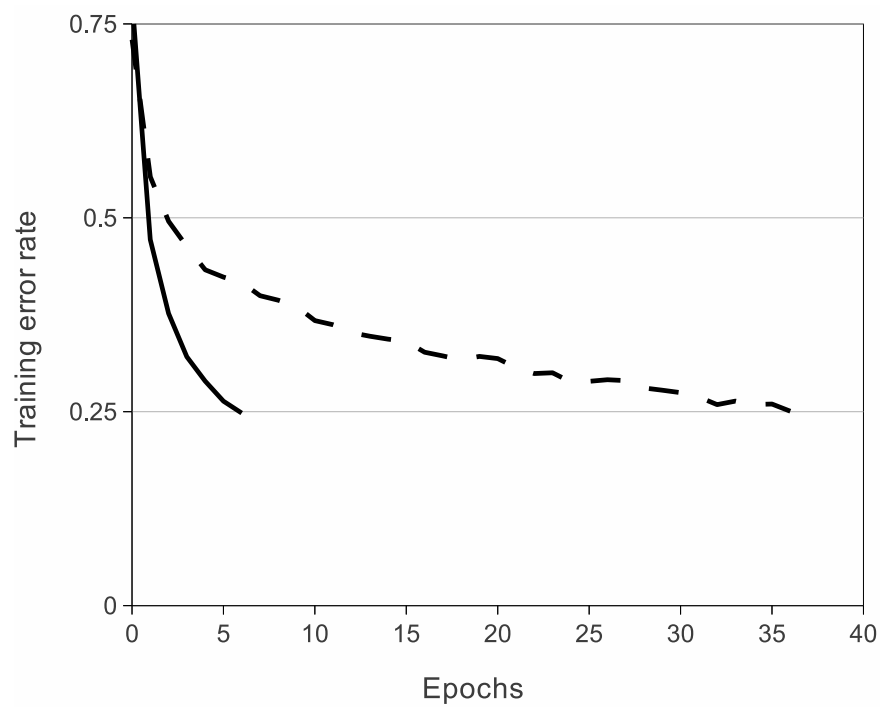
Image 1: A four-layer convolutional neural network with ReLUs (solid line) reaches a 25% training error rate on CIFAR-10 six times faster than an equivalent network with tanh neurons (dashed line).
1-2 Local Response Normalization
Nowadays, the technique Batch normalization is more popular. In 2012, the authors propose this normalization to aids the generalization.
1-3 Overlapping Pooling
In the architecture of LeNet-5, pooling is non-overlapping. The tests of this paper found using overlapping pooling can help to reduce the error rates by about 0.3%. Nowadays, non-overlapping pooling is used in most scenarios.
1-4 Overall Architecture
Image 2[1] shows the architecture of ALexNet.
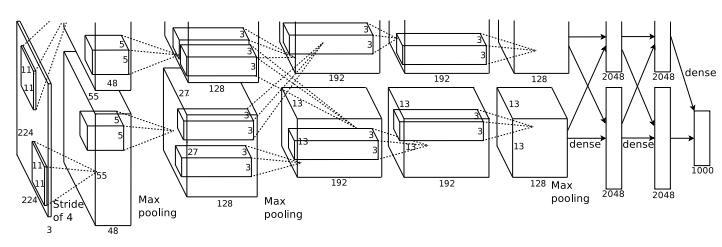
Image 2: Architecture of ALexNet
2. Implementation of GPU code to train CNN
Here we don’t dive into the details of codes. However, it’s also very important to mark this milestone of the development of CNN related techniques.
3. Reduce overfitting
Although AlexNet is trained on 1.2m images, authors found the network is still overfitting. They used 2 ways to reduce the overfitting.
Data augmentation
- Horizontal reflection
- PCA process on RGB pixel value
Drpout
Dropout consists of setting to zero the output of each hidden neuron with probability 0.5. The neurons which are “dropped out” in this way do not contribute to the forward pass and do not participate in back-propagation.
In the implementation of dropout in AlexNet, they use all the neurons but multiply their outputs by 0.5 at test time to keep the scale stable. Nowadays, it’s very popular to apply the correction of scale during the training time and do nothing at testing time.
4. Process of learning
Optimizer: SGD with momentum ($\beta = 0.9$), weight decay of 0.0005.
5. Conclusion
This post gives a quick review of AlexNet. The most important contributions AlexNet made is:
- Use RuLU as the activation function
- Implement GPU code for CNN training
Reference
[1] Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton ImageNet Classification with Deep Convolutional Neural Networks NIPS, 2012
[2] V Nair, GE Hinton Rectified Linear Units Improve Restricted Boltzmann Machines ICML, 2010