This post is a review of an old, difficult, and inspiring paper: Gradient-Based Learning Applied to Document Recognition”[1] by Yann LeCun as the first author. You can find many reviews of this paper. Most of them only focus on the architecture of the Convolution Neural Network (CNN) LeNet-5. However, I’d like to talk about some other interesting points:
- The concept of globally trainable system from the perspective of back-propagation
- How to incorporate knowledge during the design of a neural network
In fact, there are 2 networks mentioned in this paper. The first one is CNN, named LeNet-5 and the second one is called Graph Transformer Network (GTN). I talk only about the LeNet-5 in this post.
1. Globally trainable system
What’s a globally trainable system?
A system usually includes several modules. From the perspective of back-propagation, if all the modules are differentiable and the connections between the modules are also differential, in other words, the back propagation of gradients can go back from the loss function at the end to the input, it is a globally trainable system. Sometimes, we also name it as end-to-end solution for machine learning problem.
Let me give an example: we want to mark the gender of all the faces in one image? First solution is to detect the positions of all the faces and then classify the gender with the sub-image with one face. Second solution is to create a model, which takes the image as input and outputs the localization of faces as well as the corresponding gender. In the first solution, the error from the localization influence the performance of the gender classification. But we can’t use the loss function of gender classification to optimize the performance of localization if the 2 modules are separate. In the second end-to-end solution, the localization and gender detection are globally optimized.
What’s the advantage of a globally trainable system?
As partially mentioned before, we optimize all the modules together. If we have enough data, the system can achieve better performance relative to the non-globally-trainable-system.
Another more important advantage is: let the machine learn from data. If you are familiar with CNN, you probably hear that the first several hidden layers of CNN can learn the strong local pattern of image. Here are some examples in Image 1 from paper[2].

Image 1: Visualization of CNN layers
Typical-looking filters on the first CONV layer (left), and the 2nd CONV layer (right) of a trained AlexNet.
In the traditional solution, we often feed the machine learning model with the hand-design the features, as SIFT, HOG, etc. With globally trainable system, we can let the data tell us which are the most important features for a certain task.
2. Design the CNN with knowledge
In order to get self-learned features from neural network, we have to design a good architecture for the neural network. Yann LuCun indicated in his paper that no learning technique can succeed without a minimal amount of prior knowledge about the task. …. a good way to incorporate with knowledge is to tailor its architecture to the task. Now let’s focus on how to incorporate with knowledge when designing of an architecture of CNN.
In 1962, Hubel and Wiesel[3] revealed that locally-sensitive, orientation-selective neuron in the cat’s visual systems. With the constrains of local connections, the neuron can learn some basic visual features, which could be reused or grouped to form new features in the following neuron. A convolution kernel can perfectly realize this constrains of receptive field.
Until here, we find a good tool, convolution kernel, to simulate the locally-sensitive, orientation-selective neuron. Then how can we overcome some common difficulties of image classification: shift, scale and distortion invariance.
Let’s first check how human being realize image classification. We maybe act like this:
- Scan the image with some visual pattern to find some features
- Find the relation between features
- Search the relation pattern
- Find the most similar one
In the step 1, we scan the images with certain pattern. So we can fix the weights of convolution kernel for the same feature map and generate several feature maps.
In the step 2, we suppose the exact position of the feature are less important than the relative position of the feature to other features. So we can progressively reduce the spatial resolution (Sub-sampling). However, we lose information when reducing the image resolution. That’s why we need to increase the number of feature maps to keep the useful information as much as possible.
With all these knowledge, we have the general principle to design a CNN.
- Use convolution kernel
- Shared weights
- Sub-sampling and increasing the number of feature maps
3. Architecture of LeNet
3-1. LeNet-5
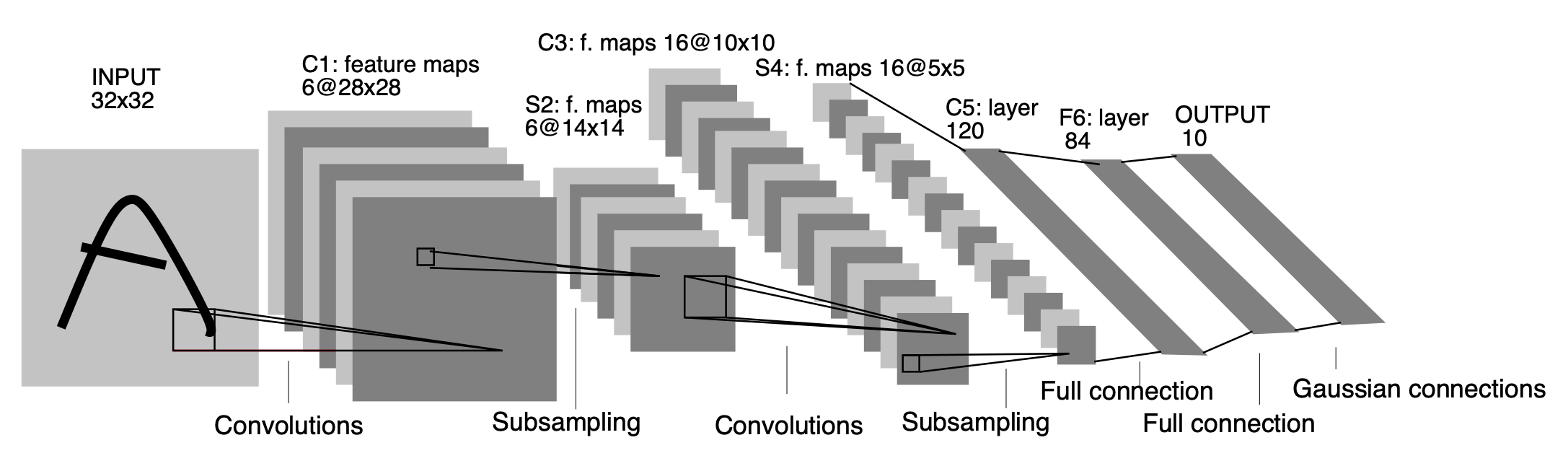 {: .center-block :}
{: .center-block :}
Image 2: Architecture of LeNet-5
Image 2[1] shows the architecture of LeNet-5.
3-2. Boosted LeNet-4
LeNet-4 is a simplified LeNet-5. It contains 4 first-level feature maps, followed by 16 sub-sampling map. We consider LeNet-4 is a weaker classifier compared to LeNet-5. Yann LuCun applied the boosting technique to LeNet-4, marked boosted LeNet-4. The boosting method reaches better performance than LeNet-5 of accuracy.
4. Other interesting points
In the domain of research of machine learning, we always mention the three key aspects to develop new methods. Yann LuCun also mentioned these in his paper:
- Machine with high capacity of computation is in low cost
- Large database is available
- Powerful machine learning techniques are available
We should also consider these factors in our own products.
5. Conclusion
In this post, I shared my understanding of how to design a neural network. I believe it’s helpful in the practice of implementing and modifying a CNN.
To sum up:
- Check the computational capacity, available database, technical support before start a machine learning project.
- Once the project starts, try to get the prior knowledge about the project as much as possible.
- Use these knowledge to design your own network.
Reference
[1] LeCun, Yann and Bottou, Léon and Bengio, Yoshua and Haffner, Patrick Gradient-Based Learning Applied to Document Recognition IEEE, 1998
[2] Understanding and Visualizing Convolutional Neural Networks
[3] D. H. Hubel, T. N. Wiesel Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex The Journal of Physiology, 1962