1. Introduction
In this post, I write about reviews of some ResNet concerned paper, which includes ResNet, ResNeXt, SENet, SKNet, and ResNeSt. Since the publication of VGG net, lots of efforts are made to develop more efficient and more modular network backbone. The most popular 2 models are Inception and ResNet.
Inception proposes multi-path in convolution and the Google researchers have done lots of experiments to tune Inception and given useful practices. From my perspective, Inception is a great network, while it’s not modular enough. We can’t directly stack Inception modules, since the hyper-parameters of Inception modules are manually set.
ResNet follows the VGG design principles and add identity shortcut in the to residual module. There is no hyper-parameter to tune. So I consider ResNet as a network easy to modify and good for the first tries of a new project. I totally support that the network architecture should be fine tuned, but it should be done in the later stage of the development. Some quick implementation and good enough models are more friendly in the beginning of the project.
Let’s first have a quick introduction to all the networks discussed in this post.
- ResNet: the first one to introduce identity shortcut to stabilize the training of deep neural network
- ResNeXt: bring the idea multi-path to ResNet
- SENet: integrate attention mechanism to ResNet
- SKNet: add adaptive receptive field of convolution
- ResNeSt: integrate attention mechanism, multi-path and brach-selection to ResNet
2. ResNet
2-1. Design Purpose
The main purpose of the design of ResNet[1] is to train deeper neural networks. Back to 2015, it’s commonly believed that the deeper neural networks own more powerful representational ability. Since the batch normalization solves the vanishing of gradient, the training of deep neural networks is possible. However, the experiments show that the deep neural network even perform worse than the shallower one. The authors proposed to add identity shortcut convolution. THe shortcut ensures that a deeper network can have at least the same performance as the shallower one.
2-2. Residual Module
The following image shows the structure of a residual module.
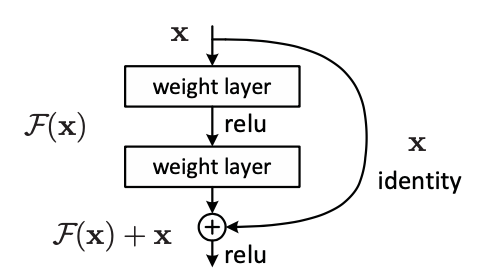
In the implementation, the authors add bottleneck design to reduce the computational cost as below.
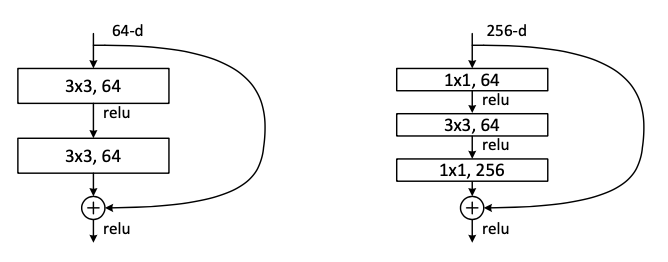
2-3. Contribution
- Speed up the training
- Improve the performance of classification
- Release the power of deeper neural network
3. ResNeXt
3-1. Design Purpose
Inspired by Inception, ResNeXt integrates the multi-path into ResNet. As mentioned before, the multi-path in Inception is well designed by doing huge number of experiments. The authors create a multi-path model with more general representation. The number of multi-path, the depth and the width of a neural network are considered as the important parameters to design. The paper also discusses the augmented computations when increasing the 3 parameters.
3-2. Multi-path Module
The image below shows the structure of multi-path module.
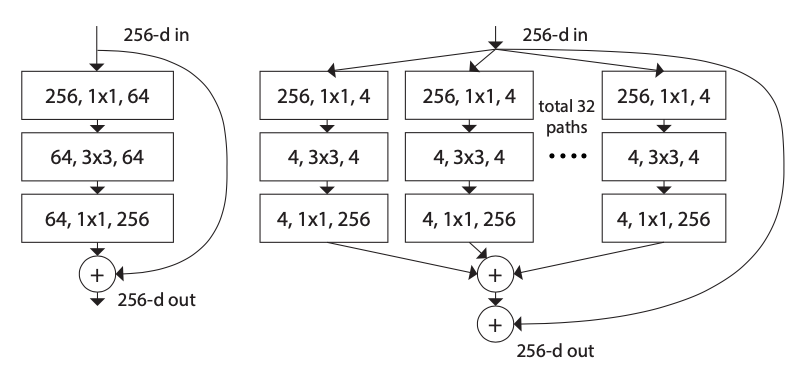
Note: I think the multi-path is very different from grouped convolution. Grouped convolution divides the input channels into several groups. But multi-path uses the same input in different path. I would like to understand each path represents a embedding space. For example, the network encode the 256 channels to 4 channels in the image above. Moreover, there are 32 different sets of 4 channels, which means 32 different embedding space. While in the left structure, there is only one embedding space of 64 dimensions. Every path tries to keep few important information by encoding then decodes the essential information to original size.
4. SENet
4-1. Design Purpose
ResNet and ResNeXt focus on the operation on the spatial information. SENet develops channel-wise operation by introducing the attention mechanism. The authors also names it as recalibration. With the weights generated from the attention mechanism or recalibration, SENet rescale the value in different channel.
4-2. Attention Mechanism
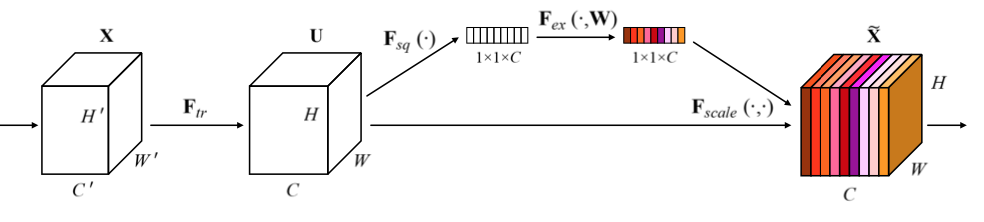
The attention mechanism of SENet includes 3 parts:
- Squeeze: Global average pooling is used to get global information embedding
- Excitation: Encode and decode to get adaptive recalibration
- Scale by channel-wise multiplication of excitation and input
5. SKNet
5-1. Design Purpose
Selective Kernel Networks (SKNet) is designed to automatically choose the size of receptive field. The input will be processed by several kernels with different size (e.g. $33$, $55$).
5-2. Selective kernel
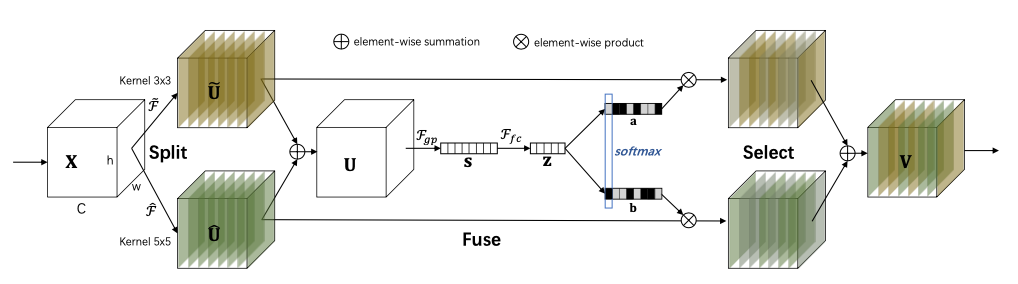
- split: Perform convolutions with kernels of different size, (n kernels)
- fuse: Element-wise adding of results processed by different kernels
- select: The fused information is firstly processed by global embedding and dimension reduction. The output is processed by 2 different matrix (which is learned during training) to generate n softmax value to scale the information generated by step 1, then do element-wise summation of the rescaled information.
6. ResNeSt
6-1. Design Purpose
ResNeSt is said to be an approach to integrate all the module together.
6-2. Module structure
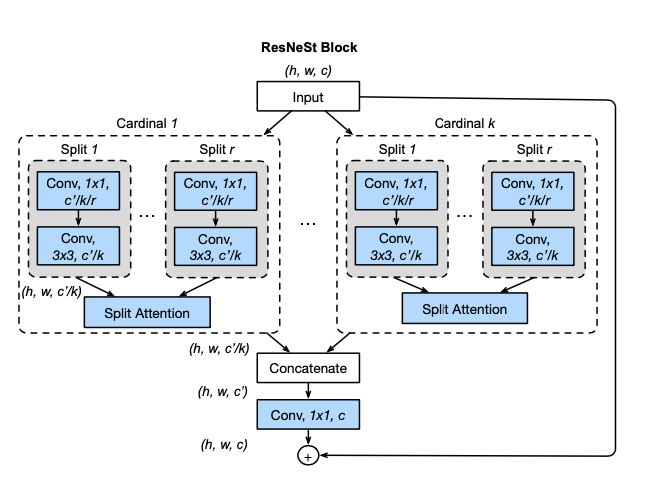
Note: ResNeSt firstly performs as ResNeXt to apply multi-path of the input, then in each cardinal (path) the split attention is used. In the SKNet, the split is done by apply convolution with different kernel size and the purpose is to select best kernel size channel-wise. However, ResNeSt do convolution with the kernels with same size. The authors also mention it’s branch-selection. I think it’s more like to generate several model and ensemble them together with split attention. There is some differences here comparing to SKNet.
7. Conclusion
Compared to network architecture search (NAS), such as efficientNet and Inception, I prefer to use ResNet family to have a first try of the solution of deep learning to a special problem. ResNet integrates the multi-path, split, attention-mechanism with few hyper-parameters. This can quickly give us a baseline of the performance, which can be improved by fine tune the hyper-parameters later.
Reference:
[1] He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian Deep residual learning for image recognition CVPR 2016
[2] Xie, Saining and Girshick, Ross and Doll{'a}r, Piotr and Tu, Zhuowen and He, Kaiming Aggregated residual transformations for deep neural networks CVPR 2017
[3] Hu, Jie and Shen, Li and Sun, Gang Squeeze-and-excitation networks CVPR 2018
[4] Li, Xiang and Wang, Wenhai and Hu, Xiaolin and Yang, Jian Selective kernel networks CVPR 2019
[5] Zhang, Hang and Wu, Chongruo and Zhang, Zhongyue and Zhu, Yi and Zhang, Zhi and Lin, Haibin and Sun, Yue and He, Tong and Mueller, Jonas and Manmatha, R and others ResNeSt: Split-Attention Networks arXiv preprint arXiv:2004.08955 2020