1. Introduction
To reproduce a deep neural network model, I have to get clear of three important elements:
- Network architeture
- Loss function
- Training practices
Because YOLO V3 technical report[3] is very clear about the network and loss function, I talk about my experiences of these 2 elements.
2. Network Architecture
Image 1[4] shows clearly the structure of YOLO V3 network.
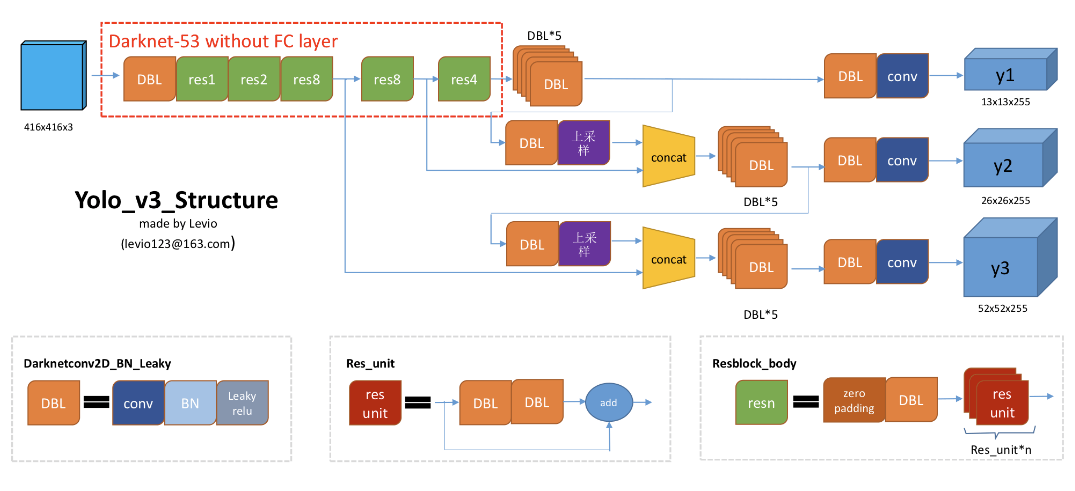 {: .center-block :}
{: .center-block :}
Image 1: Architecture of YOLO V3 network
The purple block with Chinese characters means Upsampling.
Combine Image 1 and Image 2[3], we could get clear of most parts of the network.
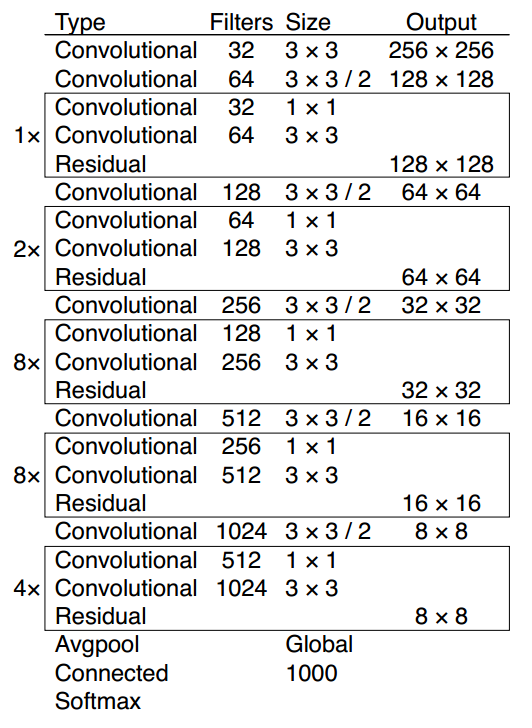
Image 2: The architecture of DarkNet-53
As described in the YOLO V3 tech report, the detection is made at three scale. We mark the feature map at 3 scales from DarkNet-53 as stride32 (last layer), stride16 (one scale before stride32), and stride8 (one scale before stride 16).
inputs, stride32, stride16, stride8 = build_darknet53_backbone(input_size)
## for the DBL*5
x = conv_bn_relu(stride32, 512, kernel_size=1, strides=1, padding="same", alpha=0.1)
x = conv_bn_relu(x, 1024, kernel_size=3, strides=1, padding="same", alpha=0.1)
x = conv_bn_relu(x, 512, kernel_size=1, strides=1, padding="same", alpha=0.1)
x = conv_bn_relu(x, 1024, kernel_size=3, strides=1, padding="same", alpha=0.1)
x = conv_bn_relu(x, 512, kernel_size=1, strides=1, padding="same", alpha=0.1)
lobj_pred = conv_bn_relu(x, 1024, kernel_size=3, strides=1, padding="same", alpha=0.1)
lobj_pred = Conv2D(filters=cell_pred_dim, kernel_size=1, strides=1, padding="same")(lobj_pred)
x = conv_bn_relu(x, 256, kernel_size=1, strides=1, padding="same", alpha=0.1)
x = UpSampling2D(2)(x)
x = tf.concat([stride16, x], axis=-1)
x = conv_bn_relu(x, 256, kernel_size=1, strides=1, padding="same", alpha=0.1)
x = conv_bn_relu(x, 512, kernel_size=3, strides=1, padding="same", alpha=0.1)
x = conv_bn_relu(x, 256, kernel_size=1, strides=1, padding="same", alpha=0.1)
x = conv_bn_relu(x, 512, kernel_size=3, strides=1, padding="same", alpha=0.1)
x = conv_bn_relu(x, 256, kernel_size=1, strides=1, padding="same", alpha=0.1)
mobj_pred = conv_bn_relu(x, 512, kernel_size=3, strides=1, padding="same", alpha=0.1)
mobj_pred = Conv2D(filters=cell_pred_dim, kernel_size=1, strides=1, padding="same")(mobj_pred)
x = conv_bn_relu(x, 128, kernel_size=1, strides=1, padding="same", alpha=0.1)
x = UpSampling2D(2)(x)
x = tf.concat([stride8, x], axis=-1)
x = conv_bn_relu(x, 128, kernel_size=1, strides=1, padding="same", alpha=0.1)
x = conv_bn_relu(x, 256, kernel_size=3, strides=1, padding="same", alpha=0.1)
x = conv_bn_relu(x, 128, kernel_size=1, strides=1, padding="same", alpha=0.1)
x = conv_bn_relu(x, 256, kernel_size=3, strides=1, padding="same", alpha=0.1)
x = conv_bn_relu(x, 128, kernel_size=1, strides=1, padding="same", alpha=0.1)
x = conv_bn_relu(x, 256, kernel_size=3, strides=1, padding="same", alpha=0.1)
sobj_pred = Conv2D(filters=cell_pred_dim, kernel_size=1, strides=1, padding="same")(x)
Loss function
The loss function is not detailed in the tech report. I have to review the source code in C to have some clues. Here are the source code from [5]
float delta_yolo_box(box truth, float *x, float *biases, int n, int index, int i, int j, int lw, int lh, int w, int h, float *delta, float scale, int stride)
{
box pred = get_yolo_box(x, biases, n, index, i, j, lw, lh, w, h, stride);
float iou = box_iou(pred, truth);
float tx = (truth.x*lw - i);
float ty = (truth.y*lh - j);
float tw = log(truth.w*w / biases[2*n]);
float th = log(truth.h*h / biases[2*n + 1]);
delta[index + 0*stride] = scale * (tx - x[index + 0*stride]);
delta[index + 1*stride] = scale * (ty - x[index + 1*stride]);
delta[index + 2*stride] = scale * (tw - x[index + 2*stride]);
delta[index + 3*stride] = scale * (th - x[index + 3*stride]);
return iou;
}
void delta_yolo_class(float *output, float *delta, int index, int class, int classes, int stride, float *avg_cat)
{
int n;
if (delta[index]){
delta[index + stride*class] = 1 - output[index + stride*class];
if(avg_cat) *avg_cat += output[index + stride*class];
return;
}
for(n = 0; n < classes; ++n){
delta[index + stride*n] = ((n == class)?1 : 0) - output[index + stride*n];
if(n == class && avg_cat) *avg_cat += output[index + stride*n];
}
}
....
# line 238
*(l.cost) = pow(mag_array(l.delta, l.outputs * l.batch), 2);
float mag_array(float *a, int n)
{
int i;
float sum = 0;
for(i = 0; i < n; ++i){
sum += a[i]*a[i];
}
return sqrt(sum);
}
As far as I understand, the loss function is the sum of square error of the box center, width and height of box, objectness probability, class probabilities.
This is almost same as the loss function of YOLO V1, the sum of 5 parts:
- $\lambda_{coord} \sum_{i=0}^{S^2} \sum^B_{j=0} \mathbb{1}_{ij}^{obj} [(x_i - \hat{x_i})^2 + (y_i - \hat{y_i})^2]$
- $\lambda_{coord} \sum_{i=0}^{S^2} \sum^B_{j=0} \mathbb{1}_{ij}^{obj} [(w_i - \hat{w_i})^2 + (h_i - \hat{h_i})^2]$
- $\sum_{i=0}^{S^2} \sum^B_{j=0} (C_i - \hat{C_i})^2$
- $\sum_{i=0}^{S^2} \sum^B_{j=0} \mathbb{1}_{ij}^{obj} (C_i - \hat{C_i})^2$
- $\sum_{i=0}^{S^2} \sum_{c \in classes} \mathbb{1}_{i}^{obj} (p_i(c) - \hat{p_i}(c))^2$
where: $\lambda_{coord} = (2-truth.w*truth.h)$, it’s a scale to amplify the error of box prediction in small box. truth.w and truth.h is the percentage of width and height of current box subject to width and height of image. If both of them are 1, which means the box is as large as the image, the $\lambda_{coord}$ is 1, the minimum value. For the small box, this scale becomes larger.
PS: I’m still not 100% sure about the loss function. If you have different ideas, please leave me a message.
Reference
[1] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi You Only Look Once: Unified, Real-Time Object Detection CVPR 2016
[2] Joseph Redmon, Ali Farhadi YOLO9000: Better, Faster, Stronger CVPR 2017
[3] Joseph Redmon, Ali Farhadi YOLOv3: An Incremental Improvement Tech report