Tuning the hyper-parameters of a deep learning (DL) model by grid search or random search is computationally expensive and time consuming. This technical report gives several practical suggestions and steps to choose the optimal hyper-parameters.
Some prior knowledge to fully understand this technical report:
- Overfitting/Underfitting
- Learning Rate (LR)
- Batch Size (BS)
- Momentum
- Weight Decay (WD)
1. Objective:
Review the approach to tune the hyper-parameters that significantly reduce training time and improves performance.
1-1. Where to find the clues to tune the hyper-parameters?
The test/validation loss is a good indicator of the network’s convergence and should be examined for clues. In the report, the test/validation loss is used to provide insights on the training process and the final test accuracy is used for comparing performance.
2. The effect of the hyper-parameters
A well tuned machine learning model should be neither underfitting nor overfitting.
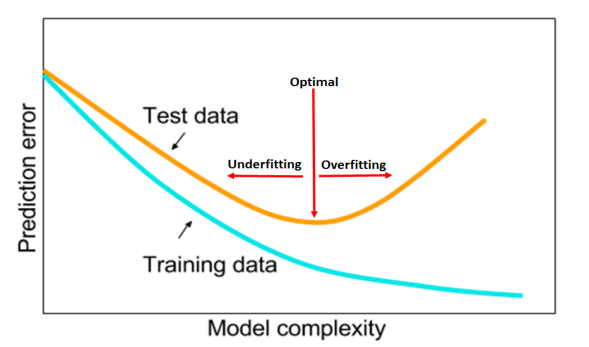
When the model is under capacity, it can’t fit well the distribution of data. When the model is too complex, it can over fit the distribution of data and have low capacity in generalization.
In practice, we raise the complexity of model to fit the training data and use the regularization techniques to overcome the overfitting. Here is a table to summarize the effect of each hyper-parameter.
| Large value | Small value | |
|---|---|---|
| Learning rate | Increase regularization Increase training speed Cause instability |
Cause overfitting |
| Batch size | Add less regularization | Add more regularization |
| Momentum | Closely related to LR | |
| Weight decay | Increase regularization Cause instability |
Decrease regularization |
Attention:
The high level of the amount of regularization can help reduce the overfitting, but it could cause instability of model when passing the limitation. So we have to balance the amount of regularization.
General principle: reducing other form of regularization and regularizing with large learning rates makes training significantly more efficient.
3. How to find a good set of hyper-parameters with a given dataset and architecture?
- Learning rate (LR): Perform a learning rate range test to find the maximum learning rate.
- Total batch size (TBS): A large batch size works well but the magnitude is typically constrained by the GPU memory.
- Momentum: Short runs with momentum values of 0.99, 0.97, 0.95, and 0.9 will quickly show the best value for momentum.
- Weight decay (WD): This requires a grid search to determine the proper magnitude.
3-1. Learning rate test
In the LR range test, training starts with a small learning rate which is slowly increased linearly throughout a pre-training run. When starting with a small learning rate, the network begins to converge and, as the learning rate increases, it eventually becomes too large and causes the test/validation loss to increase and the accuracy to decrease. The learning rate at this extrema is the largest value.
There are several ways one can choose the minimum learning rate bound:
- a factor of 3 or 4 less than the maximum bound
- a factor of 10 or 20 less than the maximum bound if only one cycle is used,
- by a short test of hundreds of iterations with a few initial learning rates and pick the largest one that allows convergence to begin without signs of overfitting.
3-2. Grid search for weight decay
When LR, BS, and Momentum are fixed, test 1e-3, 1e-4, 1e-5 and 0 as weight decay value and choose the best one.
4. Conclusion
This article summarizes:
- The effect of LR, BS, Momentum, and WD
- The steps to choose the four hyper-parameters
If you wish to have more details and explanations with experiments, please read the technical report [1].
Ref:
[1] A disciplined approach to neural network hyper-parameters: Part 1 - learning rate, batch size, momentum, and weight decay